PokéVLA: Empowering Pocket-Sized
Vision-Language-Action Model with Comprehensive World Knowledge Guidance
Demonstration Video
Abstract
Recent advances in Vision-Language-Action (VLA) models have opened new avenues for robot manipulation, yet existing methods exhibit limited efficiency and a lack of high-level knowledge and spatial awareness. To address these challenges, we propose PokeVLA, a lightweight yet powerful foundation model for embodied manipulation that effectively infuses vision-language understanding into action learning.
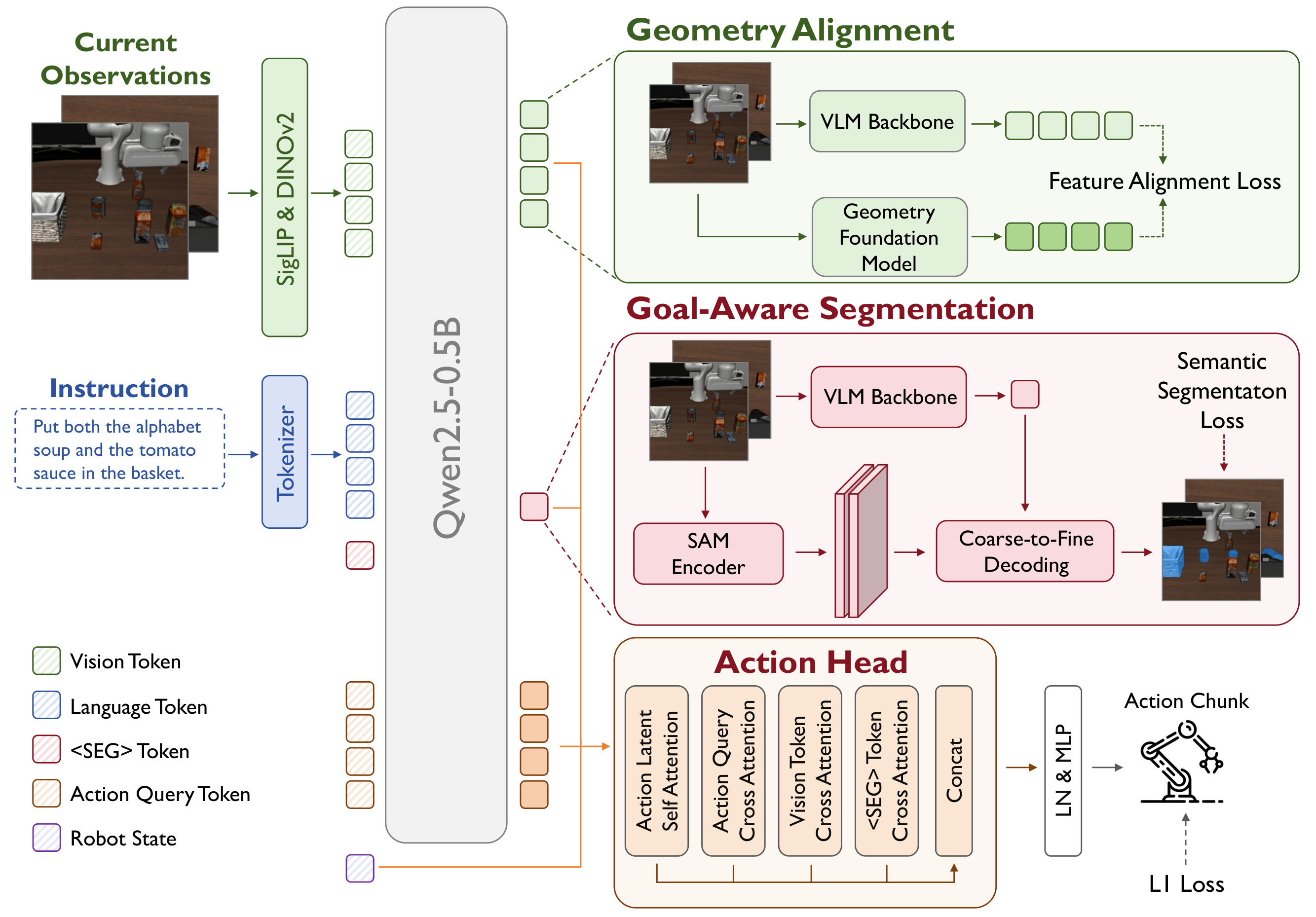
Our framework introduces a two-stage training paradigm: first, we pre-train a compact vision-language model (PokeVLM) on a curated multimodal dataset of 2.4M samples encompassing spatial grounding, affordance, and embodied reasoning tasks; second, we inject manipulation-relevant representations into the action space through multi-view goal-aware semantics learning, geometry alignment, and a novel action expert.
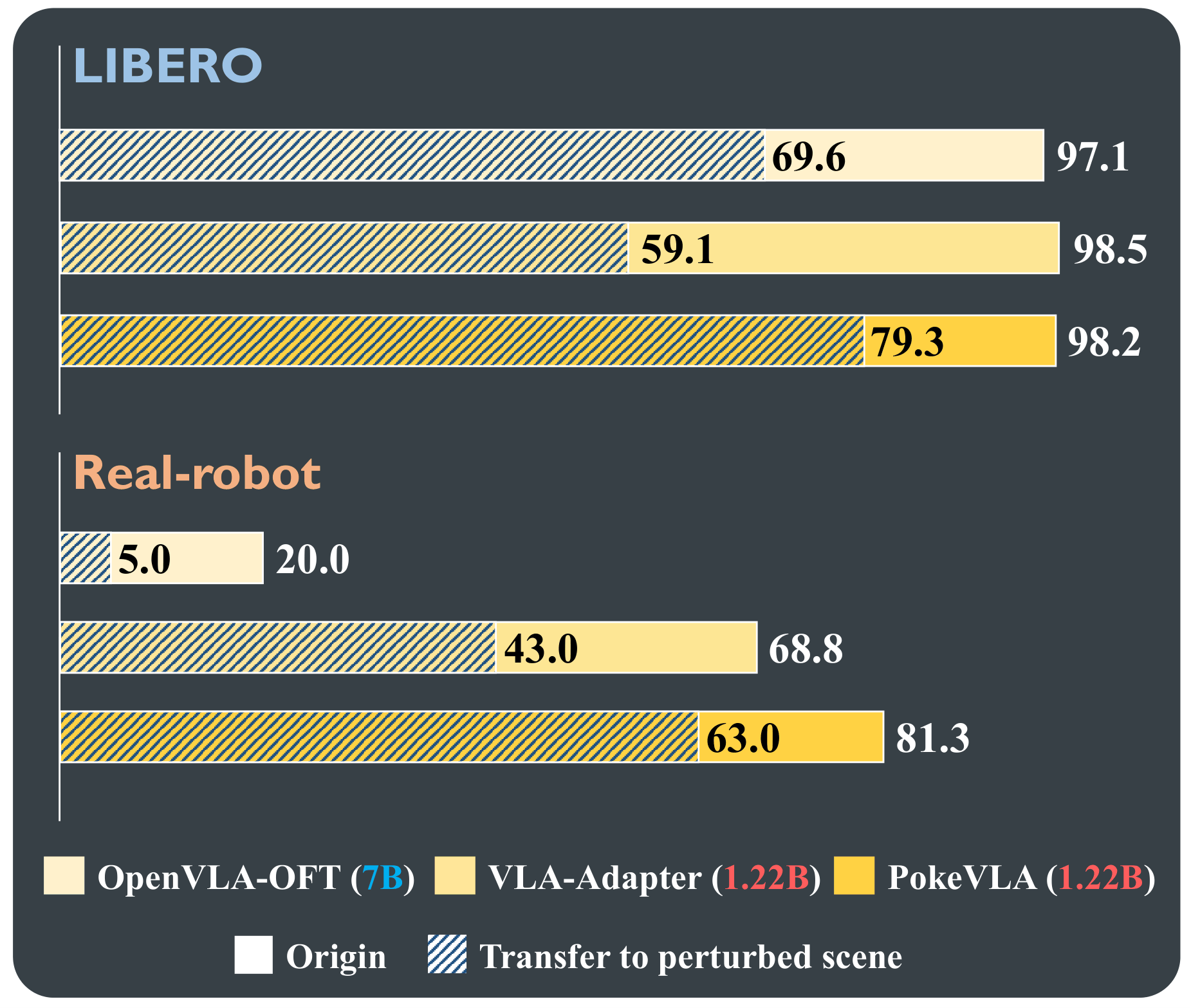
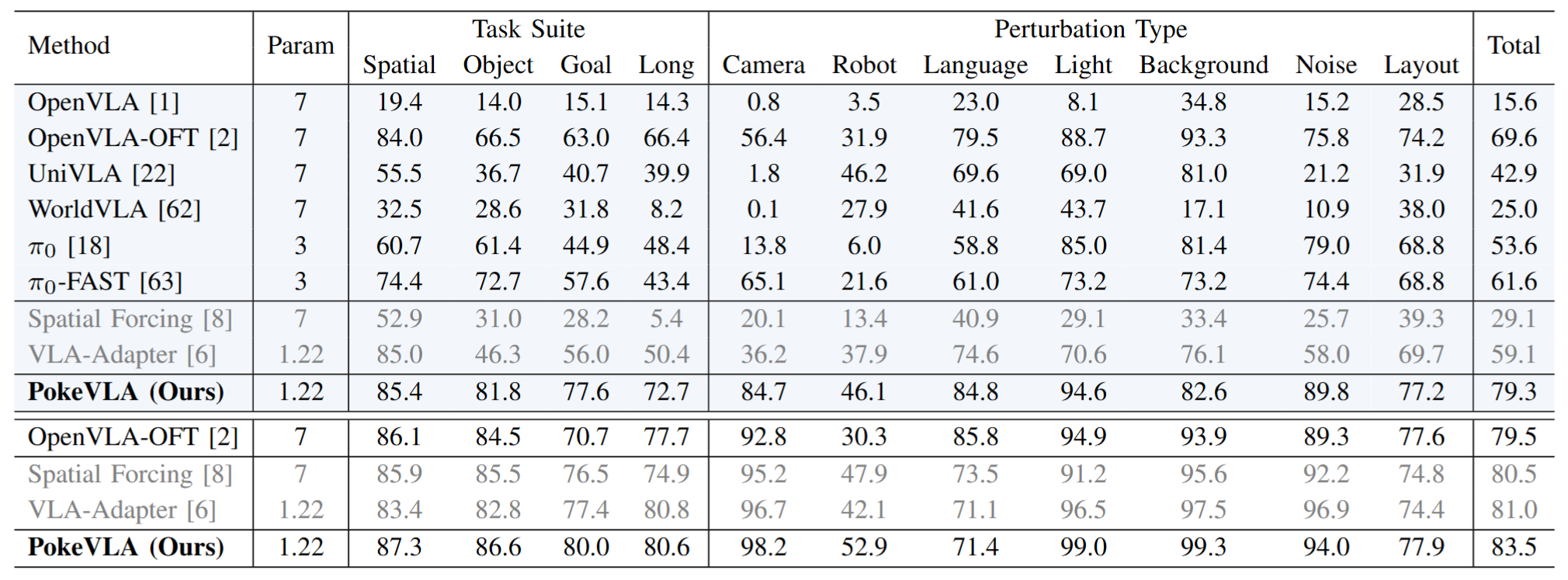
Extensive experiments demonstrate state-of-the-art performance on the LIBERO-Plus benchmark and in real-world deployment, outperforming comparable baselines in success rate and robustness under diverse perturbations. To foster reproducibility and community progress, we will open-source our code, model weights, and the scripts for the curated pre-training dataset.
Method
Results on LIBERO-Plus Benchmarks
Real-world Performance

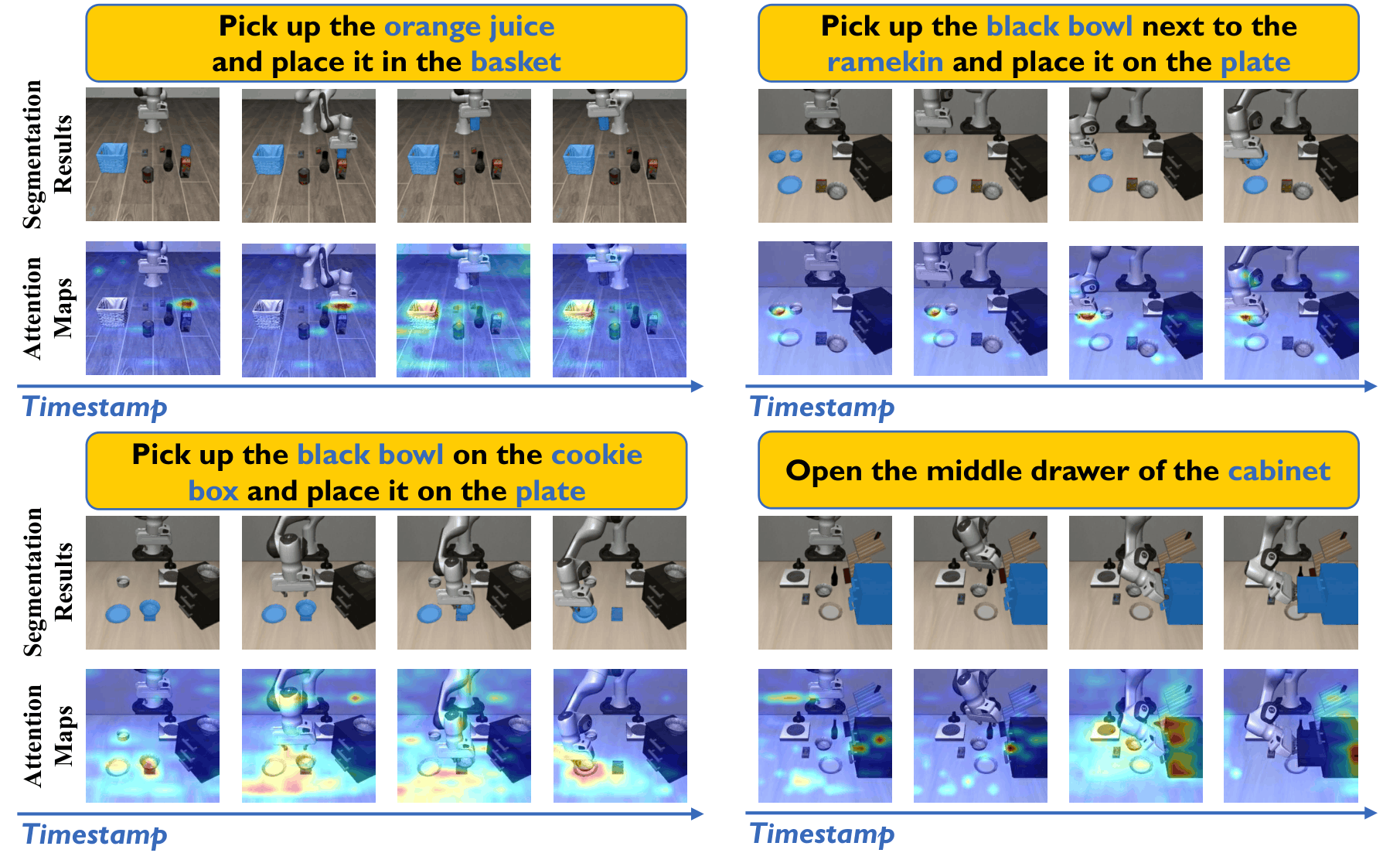
Qualitative Results